
Intro
원시형 데이터는 스택에, 참조형 데이터는 힙에 저장된다. 스택은 힙보다 빠르고, 작다.
대부분의 언어에서 일반적으로 이런 방식으로 데이터를 할당한다. 한 단계 더 깊이 생각해보면, 스택과 힙에 대해서 궁금한 점들이 생긴다.
- 정말 모든 원시형 데이터는 모조리 다 스택에, 모든 참조형 데이터는 모조리 다 힙에 저장되는 걸까?
- 참조형 데이터인 객체도 내부 속성으로 원시형 데이터를 갖고 있는데 그럼 이 내부 속성의 원시형 데이터는 스택/힙 중에 어디에 저장되는 걸까?
- 여기서 말하는 스택이 콜스택을 말하는 건가?
- 왜 스택은 힙보다 빠르고, 용량이 더 적을까?
- 근본적으로 왜 다른 메모리 공간에 각각 데이터를 저장하도록 되어있을까?
데이터 타입에 따라 메모리 어디에 할당되는지 좀 더 명확하게 알고자 내용을 정리해보았다.
Stack, Heap 데이터가 저장되는 두 가지 공간
우선 내가 짠 프로그램이 실행될 때, 실행 중에 생기는 모든 데이터는 스택과 힙이라는 메모리 공간에 저장된다. 이 스택과 힙 메모리는 어떻게 근본적으로 다르며, 그렇기 때문에 파생되는 현상들은 무엇들이 있는지 확인해볼 필요가 있다. 여기서는 자료구조로서의 스택과 힙 보다는, 메모리서의 스택과 힙을 의미한다. 스택과 힙에 대한 공통점 먼저 언급하자면, 스택과 힙은 모두 물리적으로 같은 메모리이다. 램의 한 구역으로 존재한다.
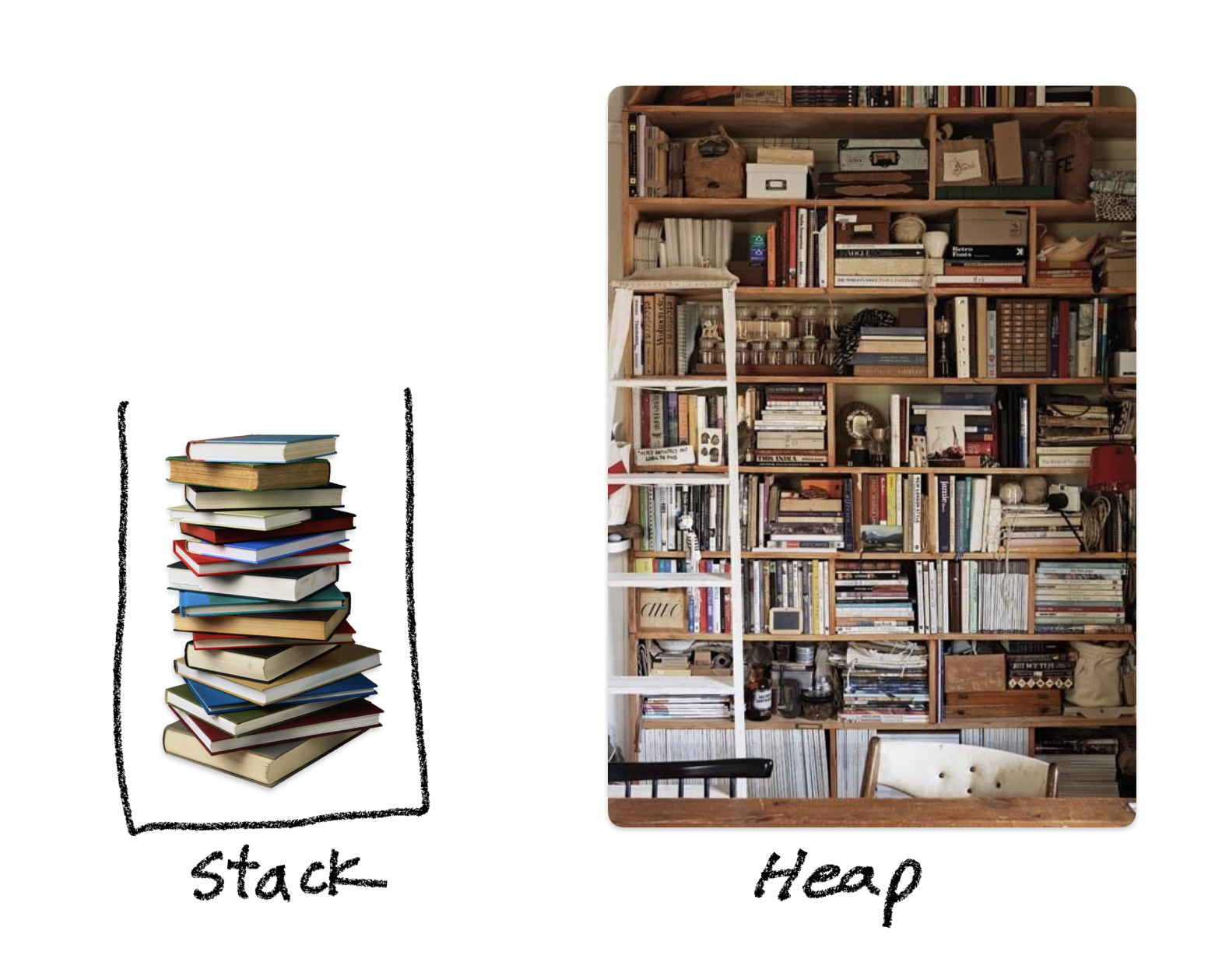 스택 mbti = 극J, 힙 mbti = 극P
스택 mbti = 극J, 힙 mbti = 극P
1. Stack
무언가를 알아볼 땐, 단어의 정의를 먼저 확인해주는 것이 인지상정. stack의 사전적 정의는 뭘까 사전에서 찾아보았다.
[noun] a pile of objects, tpically one that is neatly arranged.
순서대로 정리된 객체들의 묶음이다. (neatly = orderly) 스택은 순서가 있고, 이 순서의 기준은 후입선출(LIFO)이다. 후입선출에 따라 데이터가 입력되고 삭제된다.(할당되고 해제된다.) 뚫린 입구가 하나인 긴 박스 안에 책들이 차곡차곡 쌓여있는 이미지를 떠올리면 된다. mbti로 보면 극 이런 구조로 인해 다음과 같은 특징들이 생겨난다.
- 데이터가 연속적으로 위치해있다.
- 한 방향이다.
- 접근할 수 있는 데이터는 가장 최상위 데이터 밖에 없다.
- 모든 데이터에 마음대로 접근할 수 없다.
- 흐름을 관리할 수 있다.
- 데이터가 쌓이는 순서를 추적할 수 있다.
그렇기 때문에 프로그램의 실행 흐름을 관리하기에(=저장하기에) 적합하다.
1
A함수 -> B 함수 -> B 함수 리턴과 종료 -> 다시 A로 돌아와서 C함수 -> ....
함수의 호출 순서대로 스택에 넣고 빠지게 되고 가장 최근에 호출된, 실행중인 함수에만 접근할 수 있다. 함수가 리턴과 함께 종료되면 스택에서 꺼내어 해제한다. 이렇게 하나씩 최상위 함수들을 꺼내다보면 결국엔 이 순서가 전체 프로그램의 실행 순서를 의미하게 된다. 따라서 스택 메모리에는 프로그램의 실행과 관련된 데이터들이 저장된다. 스택을 콜스택으로 부르기도 한다.
스택에는 실행과 관련된 정보들이 저장된다는 얘기는 각 실행의 주체마다 스택을 하나씩 갖고 있다는 뜻이기도 하다. 또한 이는 스택에 접근할 수 있는 주체가 오직 하나라는 뜻이기도 하다. 실행을 호출하고 관리하는 주체만이 해당 스택에 접근할 수 있다.*(스택이 Thread safe 하다는 의미는 다른 실행 주체의 스택에 접근할 수 없기에 다른 주체로부터의 데이터 변경이 일어날 수 없어 안전하다는 말이다.) 따라서 스택은 private하다. 스택의 자원을 오직 한 주체만 접근할 수 있다.
스택이 프로그램의 실행과 관련된 정보들을 다루고 있다보니 스택은 OS가 관여하게 된다. OS가 스택의 사이즈를 결정하고, 스택에 저장되는 데이터의 입출력도 담당한다는 얘기다. 스택이 OS에 관리됨으로써 생기는 파생 현상들은 무엇들이 있을까?
스택은 힙보다 작다.
왜 스택은 비교적 적은 용량을 가지는 걸까. 스택의 크기를 결정하는 OS 입장에서 생각해보자. OS는 극강의 가성비를 원한다. 무언가 낭비되는 꼴을 못 본다. OS가 내리는 모든 결정들의 판단 기준은 다음과 같다.
- 가능하면 적은 메모리를 할당하고 싶어한다. 사용되지 않는 메모리는 최소화되어야 한다.
- 예측가능한 것을 좋아한다. 예측이 가능해야 딱 그만큼의 메모리만 할당할 수 있으니까.
따라서 OS는 가능한 적은 공간을 스택으로 할당하고 싶어하고, 그 공간에는 예측가능한 데이터들을 저장하고 싶어할 것이다. 그래서 이미 크기가 정해져 있는 원시형 타입들이 스택에 저장된다고 하는 것이다. 여기에 추가로 함수 실행과 관련된 데이터들이 저장된다.
- 함수 내에서 선언되는 변수 (참조형 데이터의 경우 힙에 저장된 참조형 데이터의 주소값이 스택에 저장된다.)
- 함수 파라미터
- 해당 함수가 호출된 환경에 대한 정보
또한, 쓰레드당 하나의 스택이 배정되기 때문에 한정된 메모리 자원상, 스택의 크기가 커지게 되면 상대적으로 더 적은 쓰레드를 생성할 수 밖에 없다.
스택은 힙보다 빠르다.
스택은 OS가 관여하기 때문에 cpu cache에 저장되는 경우가 있을 수 있고 실제로 많다고 한다. (그래서 적은 용량을 갖게 되는 이유이기도 한다.)오직 ram에만 저장되는 힙에 비해 cpu/ram 모두에 저장될 수 있는 스택이 상대적으로 빠른 것은 당연하다. (물리적 메모리 차이)
2. Heap
그럼, heap의 사전적 정의는 뭘까.
[noun] a disorderly collection of objects placed haphazardly on top of each other.
힙의 사전적 정의는 뚜렷한 기준 없이 무작위로 놓여진 것들의 집합이다. (haphazardly = lack of obvious principle of organization.) 트리 형태의 자료구조로서의 힙이 아니라 그냥 여기 저기 무작위로 데이터들이 산발적으로 저장되어 있는 그림을 떠올리면 된다. 엄청 큰 책장에 책이 아무 순서 없이 그냥 집히는 대로 꽂혀진 걸 생각하면 된다. 스택은 순서라도 있었지, 힙은 그런거 없다. mbti로 보면 극P형 인간이다.
힙은 public하다. 공공재다. 스택은 실행 주체만 접근할 수 있었던 반면, 힙은 모든 실행 주체들이 접근할 수 있다. 그래서 원시형이지만 전역변수로 선언된 데이터들도 힙에 저장된다. 어떤 실행 주체도 접근할 수 있어야 하기 때문이다. 스택에 저장하면 해당 스택을 가지고 있는 쓰레드만 접근할 수 있기 때문에 전역변수를 저장하기에는 적합하지 않다. 그렇기 때문에 힙은 스택에 비해서 느리다. 여러 주체들이 동시에 접근해야하니까.
그리고 힙의 크기는 스택에 비해 크다. 힙에는 참조형 데이터가 저장된다. 클래스, 배열, 함수 등이 저장된다. 컴파일시에는 크기를 알 수 없는 데이터들이 저장된다. 런타임시에 크기가 유동적으로 변하는 데이터들이라고 볼 수 있다. 그래서 충분한 크기가 필요하다. 힙에 저장된 참조형 데이터를 스택에 저장된 변수에서 참조한다. 또한, 힙은 OS가 관여하지 않는다. 그래서 오직 RAM에만 저장되기 때문에 읽고 쓰는데 cpu cache에도 저장되는 스택과는 비교적 느리다.
힙은 GC의 대상이된다. GC가 주기적으로 힙을 탐색하면서 해제할 영역들을 찾고 메모리를 해제한다. 스택은 OS 영역으로 GC의 대상이 아니다.
여기까지가 스택과 메모리에 대한 비교/차이점 및 그로 인한 메모리 할당 과정 특징들을 모아보았다. 아래는 스택과 힙 메모리에 대한 일반적인 차이점을 쉽고 명확하게 정리한 영상이다. Stack vs Heap Memory - Simple Explanation
궁금증 해결
앞서 Intro에서 언급했던 질문들이 답을 해보자면,
- 정말 모든 원시형 데이터는 모조리 다 스택에, 모든 참조형 데이터는 모조리 다 힙에 저장되는 걸까?
- 아니다. 데이터 타입 + 선언 시점으로 결정된다. 원시형/참조형 데이터 타입에 따라 무조건적으로 칼 같이 스택/힙에 저장되는 건 아니다. 데이터 타입 + 선언 시점도 중요한 기준이 된다. 지역변수인지/ 전역 변수인지에 따라 다른 메모리 영역이 필요하기 때문이다. 원시형이더라도 전역변수로 사용되야 하거나, 인스턴스 내의 속성으로 사용된다면 스택이 아니라 힙에 저장되어야 한다.
- 참조형 데이터인 객체도 내부 속성으로 원시형 데이터를 갖고 있는데 그럼 이 내부 속성의 원시형 데이터는 스택/힙 중에 어디에 저장되는 걸까?
- 참조형 데이터 내의 원시형 데이터는 힙에 저장된다.
- 여기서 말하는 스택이 콜스택을 말하는 건가?
- 맞다. 스택은 실행 주체마다 하나만 존재한다. 그 스택이 실행 흐름을 관리하기 때문에 콜스택이라고 부른다.
- 왜 스택은 힙보다 빠르고, 용량이 더 적을까?
- 프로그램 실행 흐름 관리에 필요한 데이터(1)와 실행 중에 생기는 데이터(2)는 다른 특성을 갖고 있기 때문. (1)은 순서를 관리해야하고, (2)는 크기가 유동적으로 변한다는 특징.
- 프로그램 실행 흐름을 OS가 관리하기 때문에 파생되는 물리적 메모리의 성능 차이.
- 근본적으로 왜 다른 메모리 공간에 각각 데이터를 저장하도록 되어있을까?
- 메모리를 두 가지 공간으로 분리하여 각 특성에 맞게 따로 저장하는 것이 더 효율적이기 때문이다.
정리
(스택오버플로우) 객체 내의 원시 데이터는 어떻게 저장되나요?
이 게시글이 궁금증의 출발이었다. 자바스크립트를 공부하다보면 원시형은 스택에, 참조형은 힙에 저장된다고 하는데, 결국엔 참조형도 원시형을 포함하고 있는데 그럼 참조형 데이터들은 도대체 어디에 저장된다는 걸까 궁금했다. 찾아보다보니 결국엔 스택과 힙 메모리의 근본적인 차이와 프로그램이 실행되면서 어떤 데이터들이 필요하고 어떤 특성을 가지고 있어서 분리되어 저장되는지에 대한 문제였다.
이 게시글에 달린 답변이 인상적이다.
ECMA 스펙을 보면 메모리 관리에 대해서 아주 조금 언급할 뿐이다. 힙이나 스택에 대해서 구체적으로 명시하고 있지 않다. 많은 프로그래밍 언어들도 메모리 관리에 대해서 그 어떤 것도 구체적으로 제한하고 있지 않다. 개발자가 프로그램을 만드는데 필요한 만큼의 정도의 제한사항만 얘기하고 있을 뿐이다. 이는 메모리 관리로부터 개발자를 자유롭게 한다. 메모리 관리를 신경쓰지 않고 자유롭게 개발하면 되는 것이다. 이 질문에 대한 답은 모르고, 알 수도 없고, 알아서도 안된다. 모든 해당 언어를 가지고 구현하는 사람들은 메모리 관리로부터 자유로워야 한다.
= 이분법적으로 절대적인 기준이 있어서 그 기준에 따라 메모리가 할당되는 것이 아니다. 이건 OS의 영역이지, 개발자의 영역이 아니다. 그렇기 때문에 내부적으로 OS가 실제로 어떻게 메모리를 할당/관리하는지 개발자는 몰라도 되고, 실제로 까볼 수도 없으므로 몰라야 하는 것이 정상이고 알 수도 없다.
맞는 말인 것 같다. 지금까지 개발하면서 메모리 관련 에러를 만난 적이 없었다. 그래도 스택/힙과 관련된 개념들 밑에 있는 과정들이 궁금했었다.